Deepseek Papers (2/3): Engram - Conditional Memory for Transformers
710 words • 4 min read • Abstract

Deepseek publishes papers. I implement them. This paper tackles another fundamental transformer problem: redundant computation.
This post covers my implementation of Engram (Conditional Memory via Scalable Lookup)—running on both Apple Silicon and NVIDIA GPUs.
| Resource | Link |
|---|---|
| Paper | arXiv:2601.07372 |
| Code | engram-poc |
| Video 1 | Engram Part 1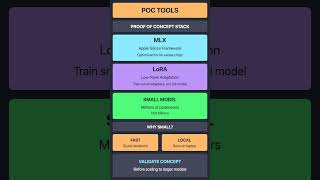 |
| Video 2 | Engram Part 2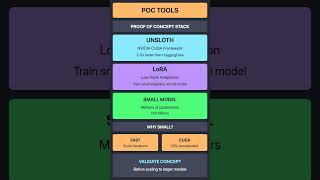 |
| Comments | Discord |
The Problem: Redundant Computation
LLMs waste compute reconstructing patterns they’ve seen before:
- Style rules repeated across files
- Common code idioms re-derived each call
- Boilerplate knowledge injected repeatedly
Attention computes everything from scratch every time. For recurring patterns, this is wasteful.
The Engram Solution: O(1) Lookup
Engram introduces conditional memory as a complementary sparsity axis. Instead of recomputing common patterns through attention, look them up in O(1) time.
Think of it as a cache for the model’s learned patterns:
| Without Engram | With Engram |
|---|---|
| Recompute pattern every call | Look up cached result |
| O(n²) attention | O(1) deterministic lookup |
| Implicit knowledge | Explicit, inspectable memory |
The PoC Approach
The full Engram paper describes in-model memory. The engram-poc repo approximates the benefits through behavioral fine-tuning:
- Pattern Injection: Training data encodes lookup-like patterns
- LoRA Adapters: Learn to recognize and consistently respond
- Evaluation: Compare baseline vs tuned model
Pattern Categories
The PoC includes 131 patterns across 4 categories:
| Category | Examples |
|---|---|
| Code Idioms | for i in range( → len(items)): |
| Factual Recall | HTTP status for 'Not Found'? → 404 |
| Format Transforms | snake_case: getUserName → get_user_name |
| Error Fixes | Fix: if x = 5: → if x == 5: |
Results
Training on SmolLM-135M-Instruct:
| Metric | Value |
|---|---|
| Training Examples | 337 |
| Training Time | ~10 seconds (M-series Mac) |
| Loss Reduction | 58.2% (4.34 → 1.82) |
Behavioral change:
Prompt: Complete: for i in range(
Baseline: "Here is a Python function that implements this approach..."
Engram-tuned: "len(items)):"
The tuned model produces direct, pattern-completing responses instead of verbose explanations.
Running the Engram Demo
git clone https://github.com/softwarewrighter/engram-poc
cd engram-poc
# Apple Silicon
uv venv && source .venv/bin/activate
uv pip install -r requirements.txt
./scripts/run_all.sh
# NVIDIA GPU (separate directory)
cd unsloth-nvidia
uv venv && source .venv/bin/activate
uv pip install torch --index-url https://download.pytorch.org/whl/cu124
uv pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
./scripts/run_all.sh
Implementation Details
| Metric | Value |
|---|---|
| Primary Language | Python |
| Source Files | 24 .py, 10 .sh, 6 .yaml |
| Estimated Size | ~3.0 KLOC |
| Frameworks | MLX-LM, Unsloth |
| Platforms | Apple Silicon, NVIDIA CUDA |
| Key Features | LoRA fine-tuning, pattern evaluation, interactive demo |
Good for you if: You want to experiment with LoRA fine-tuning, understand behavioral pattern injection, or compare MLX vs Unsloth workflows.
Complexity: Moderate. Includes extensive documentation and video recording guides. Pattern data is human-readable YAML.
Key Takeaways
-
Engram reduces redundant computation. O(1) lookup for recurring patterns beats recomputing through attention.
-
LoRA makes experimentation accessible. Fine-tune small models in seconds on a laptop.
-
Cross-platform matters. The repo runs on Apple Silicon and NVIDIA, with different tooling for each.
-
Deepseek publishes useful research. Their papers address real problems with practical solutions.
What’s Next
Part 3 will cover Engram Revisited—what happened when we moved from behavioral emulation to real hash-based memory implementation. Spoiler: it works, but not everywhere.
Resources
- Engram Paper (arXiv:2601.07372)
- engram-poc Repository
- Engram Video Part 1
- Engram Video Part 2
- Part 1: mHC
Implementing papers is the best way to understand them. Clone the repo and run the demo yourself.
Part 2 of the Deepseek Papers series. View all parts | Next: Part 3 →
Comments or questions? SW Lab Discord or YouTube @SoftwareWrighter.
