Many-Eyes Learning: Intrinsic Rewards and Diversity
1393 words • 7 min read • Abstract

In Part 1, we demonstrated that multiple scouts dramatically improve learning in sparse-reward environments. Five scouts achieved 60% success where a single scout achieved 0%.
This post explores how scouts explore: intrinsic rewards that drive novelty-seeking behavior, and what happens when you mix different exploration strategies.
| Resource | Link |
|---|---|
| Code | many-eyes-learning |
| Part 1 | Solving Sparse Rewards with Many Eyes |
| Video | Many-Eyes Learning: Watch AI Scouts Explore |
Recap: The Many-Eyes Architecture
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Scout 1 │ │ Scout 2 │ │ Scout N │
│ (strategy A)│ │ (strategy B)│ │ (strategy N)│
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
v v v
┌─────────────────────────────────────────────────┐
│ Experience Buffer │
└─────────────────────────────────────────────────┘
│
v
┌─────────────────────────────────────────────────┐
│ Shared Learner │
└─────────────────────────────────────────────────┘
Scouts are information gatherers, not independent learners. They explore with different strategies, pool their discoveries, and a shared learner benefits from the combined experience.
New Scout Strategies
CuriousScout: Count-Based Novelty
IRPO formalizes intrinsic rewards as the mechanism that drives scout exploration. CuriousScout implements count-based curiosity:
class CuriousScout(Scout):
def __init__(self, bonus_scale: float = 1.0):
self.state_counts = defaultdict(int)
self.bonus_scale = bonus_scale
def intrinsic_reward(self, state):
count = self.state_counts[state]
return self.bonus_scale / sqrt(count + 1)
How it works:
- Track how many times each state has been visited
- Reward =
bonus_scale / √(count + 1) - Novel states get high rewards; familiar states get diminishing returns
The intuition: A curious scout is drawn to unexplored territory. The first visit to a state is exciting (reward = 1.0). The fourth visit is mundane (reward = 0.5). This creates natural pressure to explore widely.
OptimisticScout: Optimism Under Uncertainty
A different philosophy: assume unknown states are valuable until proven otherwise.
class OptimisticScout(Scout):
def __init__(self, optimism: float = 10.0):
self.optimism = optimism
def initial_q_value(self):
return self.optimism # Instead of 0
How it works:
- Initialize all Q-values to a high value (e.g., 10.0)
- The agent is “optimistic” about unvisited state-action pairs
- As it explores and receives actual rewards, Q-values decay toward reality
The intuition: If you’ve never tried something, assume it might be great. This drives exploration without explicit novelty bonuses.
Strategy Comparison
| Strategy | Mechanism | Best For |
|---|---|---|
| Random | Uniform random actions | Baseline, maximum coverage |
| Epsilon-Greedy | Random with probability ε, greedy otherwise | Balancing exploit/explore |
| CuriousScout | Novelty bonus for unvisited states | Systematic coverage |
| OptimisticScout | High initial Q-values | Early exploration pressure |
The Diversity Experiment
Does mixing strategies help, or is it enough to have multiple scouts with the same good strategy?
Setup
- 7x7 sparse grid, 100 training episodes
- All configurations use exactly 5 scouts (fair comparison)
- 5 random seeds for statistical significance
Configurations
- Homogeneous Random: 5 identical random scouts
- Homogeneous Epsilon: 5 identical epsilon-greedy scouts (ε=0.2)
- Diverse Mix: Random + 2 epsilon-greedy (ε=0.1, 0.3) + CuriousScout + OptimisticScout
Results
| Configuration | Success Rate |
|---|---|
| Random baseline | 7% |
| Homogeneous random | 20% |
| Homogeneous epsilon | 40% |
| Diverse mix | 40% |
Analysis
Finding: Strategy quality matters more than diversity in simple environments.
- Epsilon-greedy (homogeneous or mixed) outperforms pure random
- Diverse mix performs the same as homogeneous epsilon-greedy
- Having 5 good scouts beats having 5 diverse but weaker scouts
Why doesn’t diversity help here?
In a simple 7x7 grid, the exploration problem is primarily about coverage, not strategy complementarity. Five epsilon-greedy scouts with different random seeds already explore different regions due to stochastic action selection.
Diversity likely provides more benefit in:
- Complex environments with multiple local optima
- Tasks requiring different behavioral modes
- Environments with deceptive reward structures
Web Visualization
The web visualization demonstrates Many-Eyes Learning with real-time parallel scout movement. (The upcoming video walks through this demo—the post focuses on the underlying mechanism.)
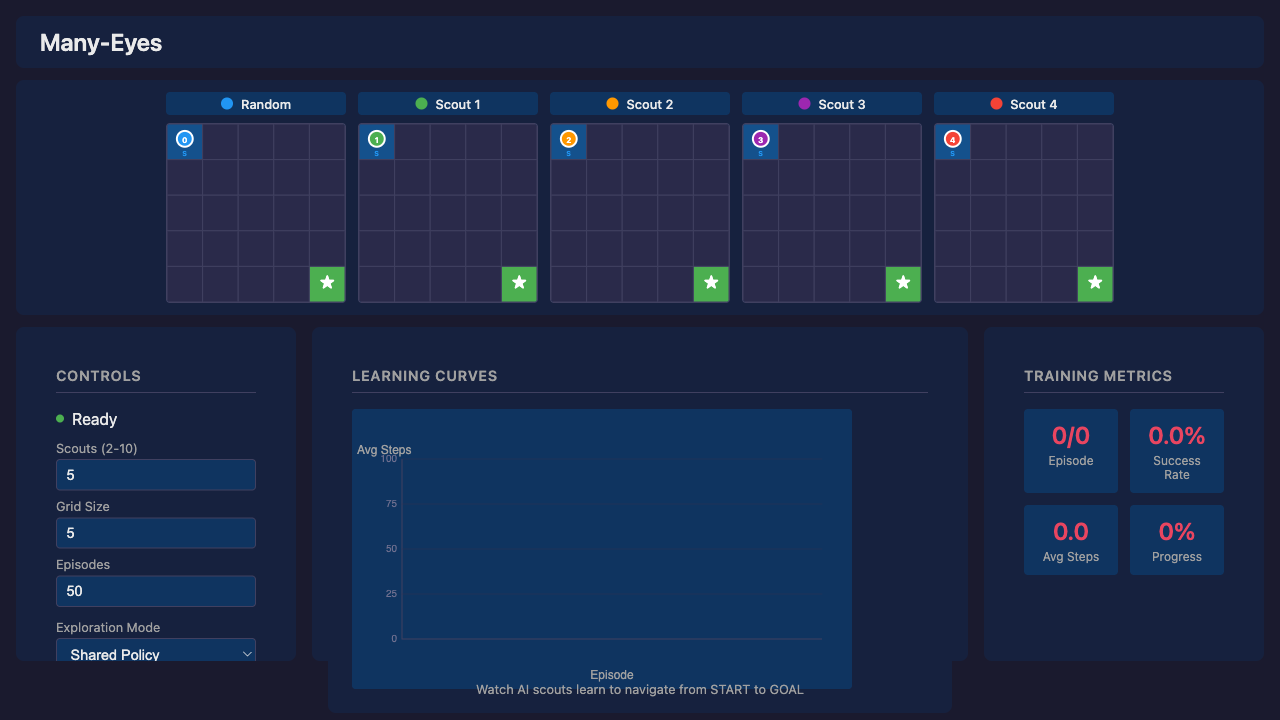
How It Works
The web version uses Q-learning with a shared Q-table (simpler than DQN for clarity). All scouts contribute to the same Q-table—the core “many eyes” concept: more explorers = faster Q-value convergence.
| Scout | Role | Epsilon | Behavior |
|---|---|---|---|
| Random | Baseline | 1.0 (constant) | Always random, never follows policy |
| Scouts 1-N | Learning Agents | 0.5-0.8 → 0.01 | Epsilon-greedy with decay |
Exploration Modes
The UI provides a dropdown to select different exploration strategies:
| Mode | Heatmap Diversity | Learning Performance |
|---|---|---|
| Shared Policy | Low (identical paths) | Best (lowest avg steps) |
| Diverse Paths | High (distinct paths) | Worse (biases override optimal) |
| High Exploration | High | Worst (never fully exploits) |
| Boltzmann | Moderate | Moderate |
The Diversity vs Performance Trade-off
There’s a fundamental trade-off between visual diversity and learning performance:
-
Shared Policy wins on performance: The “many eyes” benefit comes from diverse exploration during learning (finding the goal faster). But once Q-values converge, all scouts should follow the same optimal policy.
-
Diverse Paths sacrifices performance for visuals: Scout-specific directional biases (Scout 1 prefers right, Scout 2 prefers down) create visually interesting heatmaps but suboptimal behavior.
-
High Exploration never converges: Fixed 50% random actions means scouts never fully exploit the learned policy.
Key insight: For best learning, use Shared Policy. Use other modes to visualize how different exploration strategies affect the learning process, but expect higher average steps.
Learning Phases
| Phase | Episodes | Avg Steps | Behavior |
|---|---|---|---|
| Random | 1-5 | ~70 | All scouts exploring randomly |
| Early Learning | 5-15 | 40-60 | Policy starts forming |
| Convergence | 15-30 | 15-25 | Clear optimal path emerges |
| Stable | 30+ | 12-18 | Near-optimal with random scout noise |
Why “Average Steps to Goal”?
Success rate is coarse-grained—with 5 scouts, only 6 values are possible (0%, 20%, 40%, 60%, 80%, 100%). After ~10 episodes, all scouts typically reach the goal. Average steps shows continued policy refinement, dropping from ~70 (random) to ~8 (optimal).
Running the Visualization
./scripts/serve.sh # Open http://localhost:3200
- Yew/WASM frontend with FastAPI backend
- Speed control from 1x to 100x
- Replay mode to step through recorded training
What’s Next
Potential future directions:
| Direction | Why It Matters |
|---|---|
| Larger environments | Test scaling to 15x15, 25x25 grids |
| Scout communication | Real-time sharing vs passive pooling |
| Adaptive intrinsic rewards | Learn the reward function (closer to full IRPO) |
| Multi-goal environments | Multiple sparse rewards to discover |
Key Takeaways
-
Intrinsic rewards drive exploration. CuriousScout and OptimisticScout implement different philosophies: novelty bonuses vs optimistic initialization.
-
Strategy quality > diversity in simple environments. Five good scouts beat five diverse but weaker scouts.
-
Diversity during learning, convergence after. The “many eyes” benefit comes from diverse exploration during learning. Once Q-values converge, all scouts should follow the same optimal policy.
-
Shared Q-table enables collective learning. All scouts contribute to one Q-table—more explorers means faster convergence.
-
Visual diversity costs performance. Modes like “Diverse Paths” create interesting heatmaps but suboptimal behavior. Use “Shared Policy” for best learning results.
References
| Concept | Paper |
|---|---|
| IRPO | Intrinsic Reward Policy Optimization (Cho & Tran 2026) |
| Reagent | Reasoning Reward Models for Agents (Fan et al. 2026) |
| ICM | Curiosity-driven Exploration (Pathak et al. 2017) |
Diverse exploration, convergent execution. Many eyes see more, but the best path is the one they all agree on.
Part 6 of the Machine Learning series. View all parts
